Seriously don’t do it. Open data users don’t want it. Believe me I’ve asked:
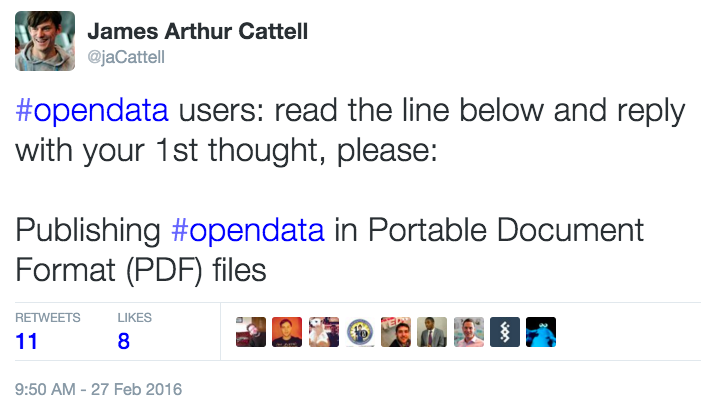
I received a lot of responses. They kept me occupied for most of the weekend. The 1st and most graphic was from the founder of OpenSensors.io:
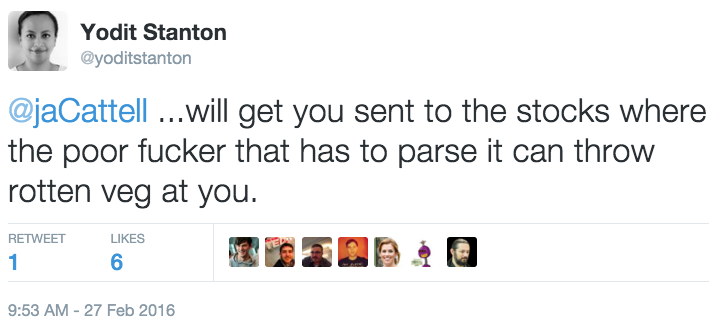
Parsing (automatically analysing the contents) of a PDF file is challenging. Without the correct knowledge and tools, any data in a PDF file is rendered inert:
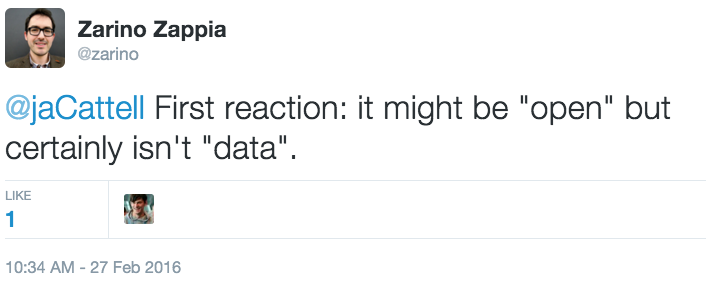
Several replies accused publishers of ignorance and obstruction: